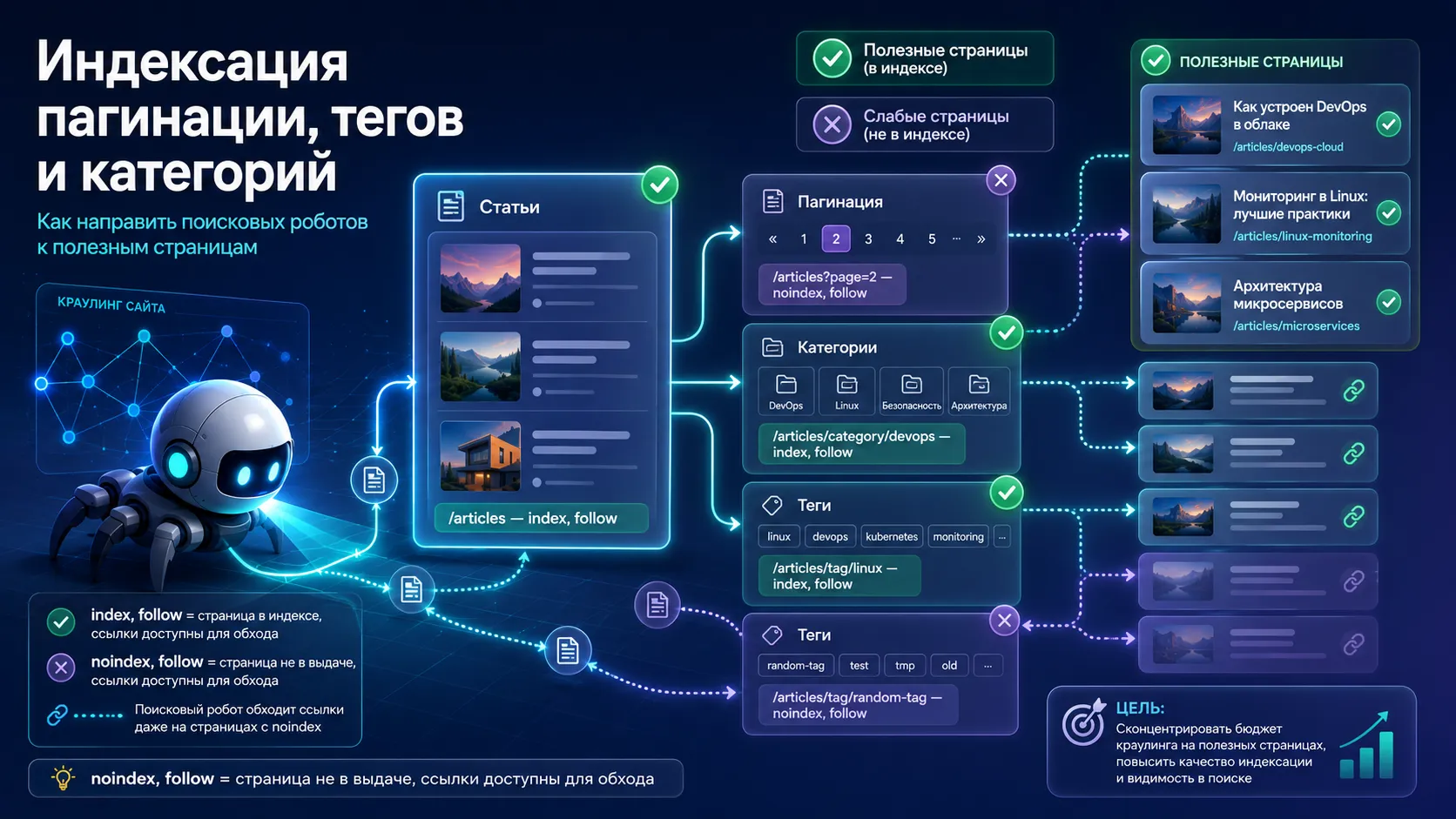
Поисковым системам полезнее видеть в индексе сильные страницы: статьи, основные разделы, важные категории и наполненные теги. Пагинацию, слабые теги, архивы и технические подборки часто лучше оставлять доступными для обхода, но убирать из выдачи через noindex, follow.
Вступление
У контентных сайтов, блогов, каталогов и новостных разделов со временем появляется много служебных страниц. Это страницы пагинации, теги с одним-двумя материалами, архивы по датам, похожие подборки, сортировки, фильтры и страницы с малым количеством контента.
Сами по себе такие страницы нормальны. Они помогают пользователю перемещаться по сайту, находить старые публикации, открывать материалы по теме и переходить между разделами. Проблема начинается тогда, когда поисковая система получает слишком много слабых URL и пытается понять, какие из них действительно заслуживают места в поисковой выдаче.
Если в индексе рядом с хорошими статьями оказываются десятки или сотни пустоватых страниц тегов, пагинации и дублей, общая структура сайта становится менее чистой. Поисковому роботу приходится тратить больше обходов на URL, которые редко дают самостоятельную пользу пользователю.
Цель грамотной настройки индексации — оставить для поиска полезные страницы и сохранить обход ссылок внутри сайта. Для этого чаще всего используют связку noindex, follow: страница доступна роботу, ссылки с неё остаются видимыми, сама страница постепенно уходит из выдачи.
Почему не все страницы стоит индексировать
Индексация нужна страницам, которые могут быть самостоятельным ответом на запрос пользователя. Например, подробная статья, главная страница блога, сильная категория с большим количеством материалов, хорошо наполненный тег или полезная подборка могут приносить поисковый трафик.
Слабые страницы работают иначе. Они часто содержат мало уникального текста, повторяют одни и те же карточки материалов, отличаются только номером страницы или показывают слишком узкую подборку. Пользователь редко ищет такую страницу напрямую, а поисковику сложнее понять её ценность.
Типичные слабые URL:
/articles?page=2;/articles?page=3;/articles/category/devops?page=2;/articles/tag/random-tag;/articles/archive/2024/05;- страницы сортировки вроде
?sort=popular; - страницы фильтров с почти одинаковым набором материалов.
Если таких URL много, они начинают размывать структуру сайта. Поисковый робот видит множество похожих страниц и тратит часть обходов на них. В результате важные статьи могут переобходиться медленнее, а новые материалы могут попадать в индекс с задержкой.
Crawl budget и внимание краулера
Краулинг — это процесс обхода сайта поисковым роботом. Робот открывает URL, читает HTML, видит ссылки и переходит дальше.
Индексация — следующий этап. Поисковая система решает, стоит ли добавить страницу в индекс и показывать её в результатах поиска.
Под «вниманием» поискового робота обычно понимают ограниченное количество ресурсов, которое поисковик готов тратить на конкретный сайт за определённый период. В SEO это часто называют crawl budget. У небольших сайтов этот вопрос обычно менее заметен, а у крупных блогов, каталогов и новостных разделов становится важнее.
Если робот регулярно встречает тысячи похожих страниц, он может тратить обходы на URL с низкой ценностью. Если структура чистая, ему проще добираться до новых статей, важных категорий и страниц, которые действительно должны ранжироваться.
Google прямо указывает, что robots.txt управляет доступом краулеров к URL и в основном используется для контроля crawler traffic, а не как надёжный способ убрать HTML-страницу из результатов поиска. Для удаления страницы из выдачи Google рекомендует использовать noindex или другие методы ограничения индексации.
Полезные страницы должны оставаться в индексе
В индексе стоит оставлять страницы, которые имеют самостоятельную ценность и могут отвечать на поисковый запрос.
Для блога, каталога или раздела статей обычно это:
- главная страница раздела статей;
- отдельные статьи;
- основные категории;
- сильные теги;
- полезные подборки;
- страницы авторов, если на них достаточно контента;
- лендинги и справочные материалы.
Пример:
<meta name="robots" content="index, follow">Такую директиву можно использовать для страниц, которые должны быть доступны поиску.
Первая страница раздела обычно полезна для индекса
Страница /articles часто является главной точкой входа в блог. На ней есть свежие публикации, внутренняя перелинковка, ссылки на категории, иногда описание раздела. Такая страница может быть полезна и пользователям, и поисковым системам.
То же относится к первой странице сильной категории:
/articles/category/devopsЕсли категория содержит много материалов, имеет понятный title, описание и логичную подборку статей, её можно оставлять в индексе.
Сильный тег работает по тому же принципу:
/articles/tag/linuxЕсли по тегу много статей, страница может быть хорошей тематической витриной. Она помогает поисковику понять, что на сайте есть кластер материалов про Linux, DevOps, Laravel, безопасность или другую тему.
Слабые страницы лучше закрывать через noindex, follow
Для слабых страниц чаще всего подходит директива:
<meta name="robots" content="noindex, follow">Она означает: страницу можно посещать, ссылки на ней можно видеть и обходить, саму страницу добавлять в поисковую выдачу не нужно.
Это важный момент. noindex, follow не запрещает поисковому роботу заходить на страницу. Робот может открыть URL, увидеть список статей, перейти по ссылкам и обновить информацию о материалах. Ограничение касается самой страницы: она не должна участвовать в выдаче как отдельный результат.
Google описывает robots meta tag как page-level способ управлять тем, как конкретная HTML-страница индексируется и показывается в поиске. Также Google подчёркивает, что такие директивы могут быть прочитаны только тогда, когда краулеру разрешён доступ к странице.
Пагинация блога
Для блога часто используют такую схему:
/articles → index, follow
/articles?page=2 → noindex, follow
/articles?page=3 → noindex, followПервая страница раздела остаётся в индексе. Страницы пагинации остаются доступными для обхода, чтобы робот мог находить старые статьи, но сами страницы пагинации не занимают место в выдаче.
Пагинация категорий
Для категорий логика похожая:
/articles/category/devops → index, follow
/articles/category/devops?page=2 → noindex, follow
/articles/category/devops?page=3 → noindex, followПервая страница категории может быть полезной посадочной страницей. Вторая и последующие страницы обычно являются продолжением списка материалов. Они помогают навигации, но редко дают самостоятельный ответ пользователю.
Слабые теги
Теговая страница становится слабой, когда по ней мало материалов. Практический ориентир — меньше 5–10 статей. Точная граница зависит от сайта.
Для маленького блога тег с 5 материалами может быть нормальным. Для крупного каталога или медиа тег с 5 материалами может выглядеть слишком слабым. Важно смотреть на качество страницы: есть ли там тематическая подборка, понятный title, описание, уникальная польза, достаточное количество ссылок на материалы.
Пример:
/articles/tag/linux → index, follow, если много статей
/articles/tag/random-tag → noindex, follow, если мало статейЕсли тег случайный, редкий, создан ради одного материала или почти дублирует категорию, его лучше закрыть от индексации.
Robots.txt подходит для ограничения обхода, но плохо решает задачу удаления из выдачи
robots.txt говорит роботам, какие URL можно или нельзя обходить. Он полезен для технических разделов, служебных маршрутов, внутренних поисковых страниц, тяжёлых фильтров и URL, которые создают нагрузку.
Пример:
User-agent: *
Disallow: /admin/
Disallow: /searchДля слабых страниц блога, тегов и пагинации robots.txt часто создаёт нежелательную ситуацию. Если закрыть страницу через Disallow, робот не сможет зайти на неё и увидеть noindex. В результате поисковик может знать сам URL по внутренним или внешним ссылкам, но не сможет прочитать мета-тег на странице.
Google предупреждает, что robots.txt не является механизмом для скрытия веб-страницы из Google Search. Если URL заблокирован в robots.txt, он всё равно может появиться в результатах поиска, например когда на него есть ссылки с других страниц.
Yandex также указывает, что директивы meta robots и X-Robots-Tag применяются для правил загрузки и индексации страниц, а если страница запрещена в robots.txt, мета-тег или HTTP-заголовок для неё не применяется.
Практический вывод: если страницу нужно убрать из индекса, но сохранить обход ссылок, лучше использовать noindex, follow, оставив URL доступным для робота.
Canonical должен показывать настоящую каноническую версию страницы
Canonical помогает поисковику понять, какая версия страницы является основной, если есть похожие или дублирующиеся URL.
Пример:
<link rel="canonical" href="https://example.com/articles">Для обычной статьи canonical обычно указывает на саму статью:
<link rel="canonical" href="https://example.com/article/example-slug">Для пагинации важно не назначать первую страницу канонической для всех последующих страниц. Страница /articles?page=2 содержит другой набор ссылок и материалов. Если поставить canonical с /articles?page=2 на /articles, поисковик может решить, что вторая страница является дублем первой. Это ухудшает понимание структуры и может мешать обнаружению старых материалов.
Google в рекомендациях по пагинации указывает, что каждой странице пагинации лучше давать уникальный URL, а в описании рекомендаций отдельно отмечает необходимость избегать canonical на первую страницу для страниц пагинации.
Более аккуратная схема:
/articles
canonical → /articles
/articles?page=2
canonical → /articles?page=2
meta robots → noindex, follow
/articles?page=3
canonical → /articles?page=3
meta robots → noindex, followТак поисковик видит, что каждая страница пагинации существует как отдельный URL, может обходить ссылки на статьи, но получает сигнал не добавлять эти страницы в выдачу.
Примеры правил для блога
Ниже — практическая схема для блога, каталога статей или новостного раздела.
| URL | Рекомендуемая директива | Логика |
/articles | index, follow | Главная страница раздела, витрина свежих материалов |
/articles?page=2 | noindex, follow | Пагинация нужна для обхода ссылок, место в выдаче ей обычно не требуется |
/articles/category/devops | index, follow | Сильная категория может собирать тематический спрос |
/articles/category/devops?page=2 | noindex, follow | Продолжение списка материалов, полезно для обхода |
/articles/tag/linux | index, follow | Тег можно индексировать, если по нему много качественных материалов |
/articles/tag/random-tag | noindex, follow | Слабый тег с малым количеством статей лучше убрать из выдачи |
/article/example-slug | index, follow | Отдельная статья является основной полезной страницей |
Пример HTML для индексируемой страницы
<meta name="robots" content="index, follow">
<link rel="canonical" href="https://example.com/articles/category/devops">Пример HTML для страницы пагинации
<meta name="robots" content="noindex, follow">
<link rel="canonical" href="https://example.com/articles/category/devops?page=2">Пример HTML для слабого тега
<meta name="robots" content="noindex, follow">
<link rel="canonical" href="https://example.com/articles/tag/random-tag">Пример HTML для статьи
<meta name="robots" content="index, follow">
<link rel="canonical" href="https://example.com/article/example-slug">Ожидаемый итог оптимизации
После настройки индексации сайт становится понятнее для поисковых систем. В индексе остаются страницы, которые действительно стоит показывать пользователям: статьи, главная страница раздела, сильные категории и наполненные теги.
Ожидаемый результат:
- меньше слабых и мусорных URL в индексе;
- выше доля полезных страниц среди всех известных поисковику URL;
- чище структура сайта;
- лучше распределяется внутренний вес между статьями и важными разделами;
- поисковикам проще находить новые материалы;
- важные страницы могут переобходиться быстрее;
- слабые страницы перестают конкурировать с полезными материалами;
- отчёты в инструментах вебмастера становятся понятнее.
Эффект не появляется мгновенно. Поисковику нужно заново обойти страницы, увидеть новые директивы, обработать их и постепенно обновить индекс. Для Google это может занять от нескольких дней до нескольких недель. Для Яндекса изменения часто видны быстрее, особенно на активно обновляемых сайтах, но мгновенного результата тоже ждать не стоит.
Скорость зависит от размера сайта, частоты обновлений, внутренней перелинковки, качества sitemap, популярности страниц и того, как часто поисковый робот посещает конкретный проект.
Частые ошибки
Закрытие пагинации через robots.txt
Если закрыть /articles?page= через robots.txt, робот может потерять доступ к ссылкам на старые статьи. Он также не сможет увидеть noindex на самой странице. Для пагинации блога чаще безопаснее оставить обход и поставить noindex, follow.
Canonical всех страниц пагинации на первую страницу
Такой вариант выглядит простым, но создаёт путаницу. Вторая, третья и последующие страницы содержат другие материалы. Canonical на первую страницу может отправить сигнал, что все эти URL являются дублями /articles.
Для пагинации обычно лучше self-canonical:
/articles?page=2 → canonical на /articles?page=2Индексация всех тегов подряд
Если каждый новый тег автоматически попадает в индекс, сайт быстро получает много тонких страниц. Особенно это заметно, когда теги создаются свободно, без редакционной структуры.
Лучше ввести правило:
если по тегу меньше 5–10 статей → noindex, follow
если тег наполнен и полезен → index, followЗакрытие важных категорий
Категории с большим количеством материалов, понятной тематикой и хорошей внутренней перелинковкой могут быть полезными посадочными страницами. Их стоит оценивать отдельно. Если категория сильная, первую страницу можно оставлять в индексе.
Использование nofollow на внутренних списках
Для страниц пагинации и тегов обычно нужен follow, чтобы поисковик мог переходить по ссылкам на статьи. nofollow на внутренних списках может ухудшить обход сайта.
Отсутствие проверки после внедрения
После изменения директив стоит проверить HTML-код страниц, canonical, sitemap и отчёты в инструментах вебмастера. Частая техническая ошибка — страница должна быть noindex, follow, а в шаблоне остаётся index, follow или canonical указывает на неправильный URL.
Вывод
Управление индексацией помогает сделать сайт понятнее для поисковых систем. В индексе должны оставаться страницы с самостоятельной ценностью: статьи, главная страница раздела, сильные категории и наполненные теги. Пагинацию, слабые теги и похожие архивные страницы лучше оставлять доступными для обхода, но закрывать от выдачи через noindex, follow.
Практическая схема для большинства блогов и каталогов выглядит так: первая страница раздела — index, follow, страницы пагинации — noindex, follow, сильные категории и теги — index, follow, слабые теги — noindex, follow, отдельные статьи — index, follow.
После внедрения нужно дать поисковикам время. Они должны заново обойти URL, прочитать новые директивы и обновить индекс. Постепенно структура выдачи станет чище, а внимание поисковых роботов будет чаще доставаться тем страницам, которые действительно важны для сайта.





