Искусственный интеллект уже не просто дописывает строки — он учится видеть весь репозиторий целиком. Разбираемся, как концепция «Repository Intelligence» меняет бэкенд-разработку: от генерации миграций до осмысленного написания кода в рамках MVC-фреймворков, и что об этом говорят реальные тесты новых моделей.
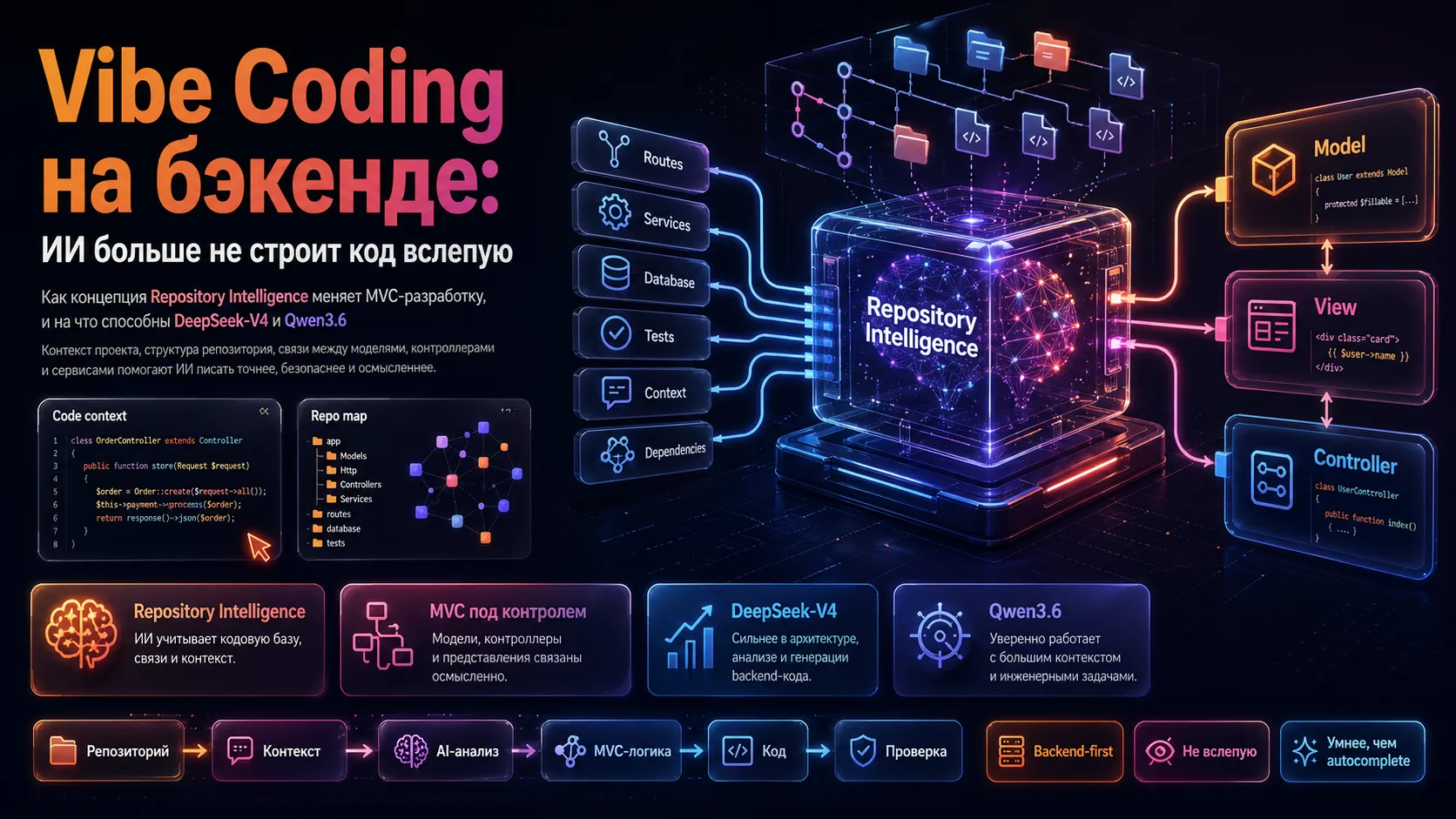
От «допиши за меня» к «пойми мой проект»: краткая эволюция ИИ-кодинга
Ещё в начале 2020-х главной задачей ИИ-ассистентов было автодополнение строк. Copilot, Codex и аналогичные инструменты подхватывали контекст текущего файла и предсказывали следующую пару токенов. Постепенно модели научились генерировать целые функции, а затем и связки файлов. К 2026 году произошёл качественный скачок: на передний план вышла концепция «Repository Intelligence» — способности ИИ не просто видеть открытый файл, а «понимать» весь проект как единую систему.
Термин «Vibe Coding», введённый Андреем Карпатым, отражает новый подход к разработке: программист описывает задачу на естественном языке, а модель сама решает, какие файлы затронуть, какие миграции создать и как вписать новый код в сложившуюся архитектуру. Однако именно здесь начинается самое интересное: насколько глубоко ИИ действительно понимает архитектурные паттерны, принятые в проекте?
Repository Intelligence: что это и почему без неё нельзя
Repository Intelligence — это способность модели работать с кодом на уровне репозитория, учитывая:
- перекрёстные зависимости между файлами,
- иерархию классов, функций и переменных,
- стилистические и архитектурные соглашения команды,
- сквозные задачи, такие как маршрутизация в контроллерах или схемы миграций БД.
Почему это критично для бэкенда? В типичном MVC-фреймворке (Laravel, Django, Spring) добавление одного нового API-маршрута требует согласованных изменений в контроллере, модели, сервисном слое, а подчас — и в тестах. Если модель не видит всей картины, она генерирует «островной» код, который ломает соглашения или вообще не компилируется.
Современные инструменты, такие как открытый проект Gortex, пытаются решить проблему фундаментально. Gortex индексирует репозиторий в виде графа знаний: каждый файл, символ, импорт, цепочка вызовов и связь типов становятся узлами, доступными для AI-агента. Как утверждают создатели, один вызов smart_context заменяет 5–10 операций чтения файлов, сокращая расход токенов примерно на 94%. Похожий подход использует фреймворк Hydra, явно выделяющий зависимости между функциями и классами через структурированное индексирование. В тестах Hydra уже превзошла традиционные RAG-подходы на 5% по метрике Pass@1.
Испытание архитектурой: как ведут себя новые модели
Чтобы проверить реальные возможности «понимания» архитектуры, сообщество активно тестирует модели последнего поколения на задачах, связанных с MVC-фреймворками и микросервисами.
DeepSeek-V4: контекст в миллион токенов и структурное мышление
Вероятно, самая громкая премьера 2026 года в области кода — DeepSeek-V4. Модель разработана с прицелом именно на репозиторное понимание. Её ключевые особенности:
- Окно в 1 млн токенов позволяет «скормить» модели значительную часть крупного проекта за один проход.
- Механизм mHC (Manifold-Constrained Hyper-Connections) переосмысливает передачу информации внутри трансформера, улучшая сохранение согласованного контекста при работе с большими кодовыми базами.
- Технология Engram Conditional Memory даёт модели избирательную память: она запоминает структуру проекта, соглашения об именах и стилистику, применяя их при генерации нового кода.
- DeepSeek Sparse Attention сокращает вычислительные затраты примерно вдвое, не жертвуя точностью, что делает реальным локальный запуск на двух RTX 3090.
Практические тесты показывают, что DeepSeek-V4 способна не просто генерировать изолированные функции, а выполнять сквозной рефакторинг: отслеживать импорты, поддерживать согласованность сигнатур API, находить мёртвый код и неиспользуемые зависимости. В одном из кейсов модель успешно разбирала стек вызовов в микросервисном проекте из 200+ файлов и предлагала исправления, затрагивающие от 3 до 7 файлов одновременно.
Qwen3.6-Plus: ставка на агентное исполнение
Alibaba ответила своей моделью Qwen3.6-Plus, которая делает акцент не столько на длину контекста (хотя и здесь заявлен 1 млн токенов), сколько на концепцию Agentic Coding — способность модели действовать как агент: планировать, выполнять и проверять цепочки действий.
В контексте MVC это означает, что Qwen3.6 может:
- самостоятельно прочитать несколько файлов проекта,
- спланировать последовательность изменений,
- создать миграцию,
- дополнить контроллер и модель,
- запустить тесты и при необходимости внести правки.
Модель уже доступна в облаке Alibaba и входит в открытый репозиторий Qwen на GitHub, что позволяет исследователям независимо проверять её способности.
Однако, как предупреждает сообщество разработчиков Vibe Stack, даже самые мощные модели остаются «жадными до одобрения»: если не сформулировать явный архитектурный план перед началом генерации, ИИ склонен предлагать самое простое, а не самое правильное решение.
Плюсы: рутина уходит, архитектор остаётся
Наиболее очевидный выигрыш от Repository Intelligence для бэкенд-разработчика — это делегирование рутинных операций, составляющих до 70% времени в типичном проекте. Речь о таких задачах, как:
- Создание миграций. Модель анализирует схему существующих таблиц, связи между моделями и генерирует корректный SQL/ORM-код, не нарушая целостности данных.
- Базовая логика контроллеров. CRUD-операции, валидация ввода, обработка ошибок — всё это ИИ пишет, сверяясь с принятыми в проекте соглашениями.
- Маршрутизация. Добавление новых путей в роутер с учётом middleware, префиксов и неймспейсов, уже определённых в системе.
- Написание тестов. Модель генерирует юнит-тесты и тесты API, понимая, какие сценарии уже покрыты, а какие — нет.
Таким образом, разработчик освобождает когнитивный ресурс для высокоуровневых архитектурных решений: проектирования схемы БД, выбора паттернов интеграции, оптимизации производительности. Код, создаваемый ИИ, становится «материалом», который инженер проверяет, дорабатывает и встраивает в общую картину.
Минусы: иллюзия понимания и накопление технического долга
Обратная сторона медали заключается в том, что «понимание архитектуры» со стороны модели — это всё ещё статистическая аппроксимация, а не инженерное мышление.
1. Проблема неявных контрактов.
Многие бэкенд-системы опираются на неформализованные правила: «в этом проекте мы не используем внешние ключи на уровне БД», «все сервисы обязаны оборачивать ответы в структуру ApiResponse<T>», «логирование — только через моник LoggerInterface». Если эти правила не зафиксированы в конфигурационных файлах или комментариях, модель может их нарушить, потому что её обучение проходило на «среднестатистических» кодовых базах.
2. Соблазн «Vibe Coding» без контроля.
Как иронично определяет Википедия, vibe coding — это практика, при которой разработчик может принимать сгенерированный код без тщательной проверки, полагаясь на «вайб» и последующие итерации. Для бэкенда это чревато внесением уязвимостей безопасности, утечек памяти или деградацией производительности, которые проявятся лишь под нагрузкой.
3. Качество падает с ростом контекста.
Исследования Vibe Stack подтверждают: модель, генерирующая 200 строк кода за один проход, делает в 3–5 раз больше ошибок, чем та же модель, работающая порциями по 50 строк. Отсюда рекомендация разбивать задачи на фазы: сначала план архитектуры, потом — реализация малыми батчами, затем — самостоятельный аудит.
4. Технический долг нового типа.
Если ИИ генерирует код, не соответствующий архитектурному видению, и команда принимает его «как есть», возникает «долг несогласованности». Проект постепенно превращается в лоскутное одеяло из стилей и паттернов, что затрудняет и ручную доработку, и дальнейшее применение ИИ.
Пример: генерация кода для MVC на практике
Рассмотрим модельную ситуацию: в существующем REST-приложении на Laravel нужно добавить эндпоинт /api/projects/{id}/stats, возвращающий агрегированную статистику. Задача, отлично подходящая для ИИ-ассистента с репозиторным интеллектом.
Что должна «понять» модель:
- Структура таблиц
projectsиtasks(миграции уже существуют). - Принятые в проекте названия контроллеров (например,
ProjectController, а неProjectsController). - Формат ответа — везде используется
ApiResourceилиJsonResponse. - Существующие middleware для аутентификации и rate limiting.
- Стиль валидации: FormRequest или inline-правила.
Эталонный процесс взаимодействия:
- Разработчик формулирует задачу и требует архитектурный план до написания кода: «Проанализируй текущий проект и предложи, какие файлы нужно создать или изменить».
- ИИ изучает структуру репозитория, находит модели
ProjectиTask, видит уже существующий маршрутRoute::apiResource('projects', ProjectController::class). - Модель предлагает: добавить метод
statsвProjectController, зарегистрировать роут вroutes/api.php, создать новыйStatsServiceдля бизнес-логики и тест вtests/Feature/ProjectStatsTest.php. - Разработчик утверждает план, и только после этого ИИ генерирует код поэтапно.
Такой подход, согласно практическим рекомендациям сообщества, снижает количество багов в 2–3 раза по сравнению с «генерацией вслепую».
Куда движется индустрия: от ассистента — к напарнику
Текущий тренд очевиден: от автодополнения к «Repository Intelligence», а от него — к полноценным AI-инженерам, способным не только генерировать код, но и сопровождать проект на всех стадиях жизненного цикла.
Уже сейчас такие фреймворки, как Bito и Gortex, предлагают AI-агентам готовую инфраструктуру для «понимания» кодовой базы через графы знаний, семантический поиск и LSP-обогащённые графы вызовов. Облачные платформы, подобные Cloudflare, встраивают vibe coding непосредственно в свои reference-архитектуры, позволяя генерировать и разворачивать сервисы в автоматическом режиме.
Однако ключевой вывод, который разделяют и исследователи, и практики: ИИ не заменяет архитектора, а становится его инструментом. Модели отлично справляются с рутиной и даже могут предлагать релевантные архитектурные решения, но финальная ответственность за согласованность, безопасность и эволюционную пригодность системы по-прежнему лежит на человеке.
«Repository Intelligence» — это не магия, а инженерная дисциплина: если команда поддерживает чистую архитектуру, фиксирует соглашения в конфигурациях и документации, а также обучает модель на собственной кодовой базе, тогда ИИ становится мультипликатором продуктивности. В противном случае он рискует превратиться в генератор красивого, но чужеродного кода, который лишь увеличит технический долг.
Статья подготовлена на основе открытых источников, репозиториев GitHub и исследовательских публикаций по состоянию на апрель 2026 года. Все упомянутые технологии и модели активно развиваются; перед внедрением в production-среду рекомендуется проводить пилотное тестирование.





